| kmeans k值确定 matlab,kmeans算法原理以及实践操作(多种k值确定以及如何选取初始点方法)... | 您所在的位置:网站首页 › mini batch kmeans算法原理 › kmeans k值确定 matlab,kmeans算法原理以及实践操作(多种k值确定以及如何选取初始点方法)... |
kmeans k值确定 matlab,kmeans算法原理以及实践操作(多种k值确定以及如何选取初始点方法)...
|
kmeans一般在数据分析前期使用,选取适当的k,将数据聚类后,然后研究不同聚类下数据的特点。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 为什么迭代后误差逐渐减小: SSE=
对于
对于
因此kmeans迭代能使误差逐渐减少直到不变 轮廓系数: 轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。具体计算方法如下: 对于每个样本点i,计算点i与其同一个簇内的所有其他元素距离的平均值,记作a(i),用于量化簇内的凝聚度。 选取i外的一个簇b,计算i与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作b(i),即为i的邻居类,用于量化簇之间分离度。 对于样本点i,轮廓系数s(i) = (b(i) – a(i))/max{a(i),b(i)} 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数,度量数据聚类的紧密程度 从上面的公式,不难发现若s(i)小于0,说明i与其簇内元素的平均距离小于最近的其他簇,表示聚类效果不好。如果a(i)趋于0,或者b(i)足够大,即a(i) if(i==1){ seed[i] dd tmp for(s in 1:n) { m for (j in 1:m) { if(j==1){ tmp else { tmptwo tmp if(tmp>tmptwo)tmp } } dd[s] } sumd random for(ii in 1:n) { if(random |
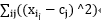
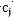 而言,求导后,当
而言,求导后,当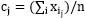 时,SSE最小,对应第(3)步;
时,SSE最小,对应第(3)步;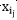 而言,求导后,当
而言,求导后,当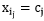 时,SSE最小,对应第(2)步。
时,SSE最小,对应第(2)步。【本文地址】